在日常开发中不会直接使用ORM框架,一般会在使用Django的时候使用Django自身的ORM框架,这里的只对ORM框架中SQLAchemy做了解就可以了,因为SQLAchemy的用法和Django中的ORM框架很类似
在 ORM 框架中 一个类就是一张表,一个属性代表一个字段,一个对象就是一行数据
ORM 框架有两类:
- db first -> 先创建数据库和表,通过代码自动生成类和对象
- code first -> 手动编写类和对象,然后通过类和对象生成表和数据
- SQLAchemy 属于 code first 这一类,而 Django 这两类都支持
1. sqlalchemy的安装
pip3 install sqlalchemy -i https://pypi.douban.com/simple # 使用豆瓣的镜像
2. pymysql的安装
pip3 install pymysql -i https://pypi.douban.com/simple # 使用豆瓣的镜像
3. 注意: SQLAchemy本身是无法操作数据库(因为SQLAchemy本身只负责将代码转换为SQL语句),必须使用 DBAPI(即: 第三方的操作数据库的模块,如:pymysql,mysqldb,……)来进行数据库的操作,所以在使用SQLAchemy前一定要下载第三方的操作数据库的模块
# 根据配置文件的不同,调用不同的DBAPI,从而实现 sqlalchemy 对数据库的操作,(在操作数据库的时候,就要使用对应的第三方模块去操作数据库,而 SQLAchemy 想去使用这些模块就要进行相关的配置)如:
# mysql 数据库
# pymysql 模块
mysql+pymysql://数据库用户名:密码,如果没有密码可以空着不填@ip地址:端口号/数据库名称?charset=utf8
# mysqldb 模块
mysql+mysqldb://数据库用户名:密码,如果没有密码可以空着不填@ip地址:端口号/数据库名称
# mysqlconnector 模块
mysql+mysqlconnector://数据库用户名:密码,如果没有密码可以空着不填@ip地址:端口号/数据库名称
# oracle 数据库
# cx_oracle 模块
oracle+cx_oracle://数据库用户名:密码,如果没有密码可以空着不填@ip地址:端口号/数据库名称?key=value&key=value...
4. 创建表 和 删除表
from sqlalchemy.ext.declarative import declarative_base
from sqlalchemy.orm import sessionmaker, relationship
from sqlalchemy import create_engine
from sqlalchemy import Column, Integer, String, ForeignKey, UniqueConstraint, Index, CHAR, VARCHAR
'''
Column -> 创建字段的方法
Integer -> 整型
String -> 字符串类型,包含了 char 和 varchar
ForeignKey -> 外键
UniqueConstraint -> 联合唯一索引
Index -> 联合普通索引
CHAR -> char
VARCHAR -> varchar
'''
Base = declarative_base() # 创建一个 Base 对象
# Users 表的类
class Users(Base): # 创建表的类一定要继承 Base
__tablename__ = 'users' # 表名
id = Column(Integer, primary_key=True, autoincrement=True) # 整型 设置主键 设置自增列
name = Column(VARCHAR(32), nullable=True, index=True) # varchar类型 允许为空 将name字段设置为索引
email = Column(String(32), unique=True) # varchar类型 或 char类型 将email字段设置为唯一索引
uid = Column(Integer)
tid = Column(Integer)
user_type_id = Column(Integer, ForeignKey('usertype.id')) # 创建外键
__table_args__ = (
UniqueConstraint('uid', 'name', name='uix_uid_name'), # 创建一个名为 uix_uid_name 的联合唯一索引
Index('index_name', 'name', 'email') # 创建一个名为 index_name 的普通联合索引
)
# UserType 表的类
class UserType(Base):
__tablename__ = 'usertype'
id = Column(Integer, primary_key=True, autoincrement=True)
title = Column(VARCHAR(32), nullable=True, index=True)
# 创建表
def create_table():
engine = create_engine("mysql+pymysql://root:@127.0.0.1:3306/db1?charset=utf8", max_overflow=5) # 通过使用第三方模块去操作数据库,且最大链接数为5
Base.metadata.create_all(engine) # 找到所有继承了 Base 的类,将这些类转换成SQL语句,然后通过第三方模块pymysql执行SQL语句创建表
# 删除表
def drop_table():
engine = create_engine("mysql+pymysql://root:@127.0.0.1:3306/db1?charset=utf8", max_overflow=5) # 通过使用第三方模块去操作数据库,且最大链接数为5
Base.metadata.drop_all(engine) # 找到所有继承了 Base 的类,将这些类转换成SQL语句,然后通过第三方模块pymysql执行SQL语句删除表
# create_table
# drop_table()
5. 操作表的固定结构
from sqlalchemy.ext.declarative import declarative_base
from sqlalchemy.orm import sessionmaker, relationship, aliased
from sqlalchemy import create_engine
from sqlalchemy import and_, or_
from sqlalchemy import Column, Integer, String, ForeignKey, UniqueConstraint, Index, CHAR, VARCHAR
Base = declarative_base()
# 创建表 - start
class Users(Base):
__tablename__ = 'users'
id = Column(Integer, primary_key=True, autoincrement=True)
name = Column(VARCHAR(32), index=True)
age = Column(Integer)
address = Column(VARCHAR(32))
utid = Column(Integer, ForeignKey('usertype.id'))
user_type = relationship('UserType', backref='xxoo')
class UserType(Base):
__tablename__ = 'usertype'
id = Column(Integer, primary_key=True, autoincrement=True)
title = Column(VARCHAR(32))
class Score(Base):
__tablename__ = 'score'
sid = Column(Integer, primary_key=True, autoincrement=True)
student_id = Column(Integer)
course_id = Column(Integer)
num = Column(Integer)
engine = create_engine("mysql+pymysql://root:@127.0.0.1:3306/db1?charset=utf8", max_overflow=5)
def create_db():
Base.metadata.create_all(engine)
def drop_table():
Base.metadata.drop_all(engine)
# create_db()
# 创建表 - end
# 操作表 - start
Session = sessionmaker(bind=engine)
session = Session() # sessoin 取一条连接对表进行操作
# 在这里编写对表中数据的增删改查
# 例如: 添加一条数据
data_obj1 = Users(name='Aimer', age=25, address='南城', utid=1)
session.add(data_obj1)
session.commit() # 和 pymysql 中的 commit 一样,如果不懂就看回 pymysql 中的 commit
session.close() # 关闭连接
# 操作表 - end
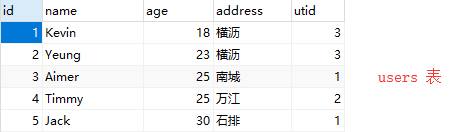

6. 添加数据
- 添加一条数据
# 表的类名(字段名='数据')
data_obj1 = Users(name='Aimer', age=25, address='南城', utid=1) # 创建一个对象,该对象就代表着一条数据 # insert into users(name,age,address,utid) values('Kevin',18,'横沥',3)
session.add(data_obj1)
- 批量添加数据
data_objs = [
Users(name='Kevin', age=18, address='横沥', utid=3),
Users(name='Yeung', age=23, address='横沥', utid=3),
Users(name='Aimer', age=25, address='南城', utid=1),
Users(name='Timmy', age=25, address='万江', utid=2),
Users(name='Jack', age=30, address='石排', utid=1),
]
session.add_all(data_objs) # insert into users(name,age,address,utid) values('Kevin',18,'横沥',3), ('Yeung',23,'横沥',3), ……
7. 查询数据
- 获取查询到的数据
- .all() -> 获取查询到的所有数据
ret = session.query(Users.name, Users.address).all()
print(ret) # [('Kevin', '横沥'), ('Yeung', '横沥'), ……]
- .first() -> 获取查询到的所有数据的第一条数据
ret = session.query(Users.name, Users.address).first()
print(ret) # ('Kevin', '横沥')
- 在查询数据的时候如果不加 .all() 或 .first() 会返回一个迭代器,直接循环迭代器获取查询到数据
ret = session.query(Users.name, Users.address)
for row in ret:
print(row) # ('Kevin', '横沥')
print(row[0]) # Kevin
print(row.name) # Kevin
- 注意: 在查询数据的时候如果不加 .all() 或 .first() 打印会返回一条 SQL 语句
ret = session.query(Users)
print(ret) # select id, name from users;
- 查询该表的所有数据 -> 相当于 select * from 表名; -> 不建议使用
- 注意: 如果直接传入一个类名查询该表的所有字段的数据,那么返回值是一个对象列表,需要循环该对象列表获取该表所需要字段的数据
# session.query(表的类名).all()
ret = session.query(Users).all() # 将表的类名传入到 query 中,就可以查询到该表的所有数据
print(ret) # [<__main__.Users object at 0x00000281308CE898>, ……]
for row in ret:
print(row.name, row.age, row.address)
- 查询某几列的数据 -> 相当于 select 字段名,字段名 from 表名;
# session.query(表的类名.字段名, 表的类名.字段名, ……).all()
ret = session.query(Users.name, Users.address).all() # select name,address from users;
print(ret) # [('Kevin', '横沥'), ('Yeung', '横沥'), ……]
- 给表起别名
# 导入 aliased
from sqlalchemy.orm import aliased
# aliased(表的类名, name='别名')
users_alias = aliased(Users, name='users_alias')
ret = session.query(users_alias.name, users_alias.address).all()
print(ret) # [('Kevin', '横沥'), ('Yeung', '横沥'), ……]
- 条件查询 -> filter
- filter 在进行比较的时候直接使用 表的类名.字段名 == 'xxx'
# .filter(表的类名.字段名 ==/>/</>=/<= 'xxx')
ret = session.query(Users.name, Users.address).filter(Users.id > 3).all() # select name,address from users where id > 3;
print(ret) # [('Timmy', '万江'), ('Jack', '石排')]
# .filter(表的类名.字段名 ==/>/</>=/<= 'xxx')
ret = session.query(Users.name, Users.address).filter(Users.id == 3).all() # select name,address from users where id = 3;
print(ret) # [('Aimer', '南城')]
# .filter(表的类名.字段名 == 'xxx', 表的类名.字段名 > 'xxx', 表的类名.字段名 < 'xxx', ……)
ret = session.query(Users.name, Users.address).filter(Users.id >= 3, Users.id <= 5, Users.age == 25).all() # select name,address from users where id >= 3 and id <= 5 and age = 25;
print(ret) # [('Aimer', '南城'), ('Timmy', '万江')]
- 条件查询 -> filter_by
- 注意: filter_by 只能进行 = 的条件查询,不能进行其他的条件查询,如: > <
- filter_by 在进行比较的时候直接使用 字段名 = 'xxx'
# .filter_by(字段名='xxx')
ret = session.query(Users.name, Users.address).filter_by(id=3).all() # select name,address from users where id = 3;
print(ret) # [('Aimer', '南城')]
# .filter_by(字段名='xxx', 字段名='xxx', ……)
ret = session.query(Users.name, Users.address).filter_by(id=1, name='Kevin').all() # select name,address from users where id = 1 and name = 'Kevin';
print(ret) # [('Kevin', '横沥')]
- or_ 和 and_
- 注意: filter 和 filter_by 默认使用 and 进行条件查询,如果要使用 or 就要将 or_ 导入进来,且 filter_by 不能使用 or_ 和 and_
# 导入 or_ 和 and_
from sqlalchemy import or_, and_
# or_(表的类名.字段名 == 'xxx', 表的类名.字段名 > 'xxx', 表的类名.字段名 < 'xxx', ……)
ret = session.query(Users.name, Users.address).filter(or_(Users.id == 5, Users.id == 6)).all() # select name,address from users where id = 5 or id = 6;
print(ret) # [('Jack', '石排')]
# and_(表的类名.字段名 == 'xxx', 表的类名.字段名 > 'xxx', 表的类名.字段名 < 'xxx', ……)
ret = session.query(Users.name, Users.address).filter(and_(Users.id == 1, Users.name == 'Kevin')).all() # select name,address from users where id = 1 and name = 'Kevin';
print(ret) # [('Kevin', '横沥')]
- between
# .between(num, num)
ret = session.query(Users.name, Users.address).filter(Users.id.between(1, 3)).all() # select name,address from users where id between 1 and 3;
print(ret) # [('Kevin', '横沥'), ('Yeung', '横沥'), ('Aimer', '南城')]
- in_
# .in_([xx, xx, xx, ……])
ret = session.query(Users.name, Users.address).filter(Users.id.in_([1, 3])).all() # select name,address from users where id in(1,3);
print(ret) # [('Kevin', '横沥'), ('Aimer', '南城')]
# ~表的类名.字段名.in_([xx, xx, xx, ……]) 等于 not in
ret = session.query(Users.name, Users.address).filter(~Users.id.in_([1, 3])).all() # select name,address from users where id not in(1,3);
print(ret) # [('Yeung', '横沥'), ('Timmy', '万江'), ('Jack', '石排')]
- 模糊查询
# .like('%xxx%')
ret = session.query(Users.name, Users.address).filter(Users.name.like('%e%')).all() # select name,address from users where name like '%e%';
print(ret) # [('Kevin', '横沥'), ('Yeung', '横沥'), ('Aimer', '南城')]
# ~表的类名.字段名.like('%xxx%') 等于 not like
ret = session.query(Users.name, Users.address).filter(~Users.name.like('%e%')).all() # select name,address from users where name not like '%e%';
print(ret) # [('Timmy', '万江'), ('Jack', '石排')]
- 分页
# 直接在查询到的数据后面进行切片
ret = session.query(Users.name, Users.address)[0:2] # select name,address from users limit 0,2
print(ret) # [('Kevin', '横沥'), ('Yeung', '横沥')]
- 排序
ret = session.query(Users.id, Users.name, Users.age).order_by(Users.age.desc()).all() # select id,name,age from users order by age desc;
print(ret) # [(5, 'Jack', 30), (3, 'Aimer', 25), (4, 'Timmy', 25), (2, 'Yeung', 23), (1, 'Kevin', 18)]
# 对相同数据的进行二次排序
ret = session.query(Users.id, Users.name, Users.age).order_by(Users.age.desc(), Users.id.desc()).all() # select id,name,age from users order by age desc, id desc;
print(ret) # [(5, 'Jack', 30), (4, 'Timmy', 25), (3, 'Aimer', 25), (2, 'Yeung', 23), (1, 'Kevin', 18)]
- 聚合函数
- 通过 func 使用聚合函数
# 导入 func
from sqlalchemy.sql import func
ret = session.query(
func.max(Users.age),
func.min(Users.age),
func.count(Users.id),
func.sum(Users.age),
func.avg(Users.age)
).all()
print(ret) # [(30, 18, 5, Decimal('121'), Decimal('24.2000'))]
- 分组
# 导入 func,使用聚合函数
from sqlalchemy.sql import func
ret = session.query(
Users.age,
func.count(Users.age)
).group_by(Users.age).all()
print(ret) # [(18, 1), (23, 1), (25, 2), (30, 1)]
- having()
ret = session.query(
Users.age,
func.count(Users.age)
).group_by(Users.age).having(func.count(Users.age) >= 2).all()
print(ret) # [(25, 2)]
- 连表
- 方法一
ret = session.query(Users.name, Users.age, UserType.title).filter(Users.utid == UserType.id).all() # select users.name, users.age, usertype.title from users, usertype where users.utid = usertype.id;
print(ret) # [('Aimer', 25, '超级会员'), ('Jack', 30, '超级会员'), ('Timmy', 25, '白金会员'), ('Kevin', 18, '黑金会员'), ('Yeung', 23, '黑金会员')]
- 方法二 -> .join() -> 在默认情况下 .join() 会使用 inner join 进行连表查询
# 如果不加条件进行连表 .join() 会默认使用外键进行判断连表
ret = session.query(Users.name, Users.address, UserType.title).join(UserType).all() # select users.name, users.address, usertype.title from users inner join usertype on users.utid = usertype.id;
print(ret) # [('Aimer', '南城', '超级会员'), ('Jack', '石排', '超级会员'), ('Timmy', '万江', '白金会员'), ('Kevin', '横沥', '黑金会员'), ('Yeung', '横沥', '黑金会员')]
# 使用条件进行连表,在大多数情况都会使用外键进行判断连表,所以可以直接省略条件判断,这里只是为了做演示而已
ret = session.query(Users.name, Users.address, UserType.title).join(UserType, Users.utid == UserType.id).all() # select users.name, users.address, usertype.title from users inner join usertype on users.utid = usertype.id;
print(ret) # [('Aimer', '南城', '超级会员'), ('Jack', '石排', '超级会员'), ('Timmy', '万江', '白金会员'), ('Kevin', '横沥', '黑金会员'), ('Yeung', '横沥', '黑金会员')]
# isouter=True 将 inner join 该变成 left join
ret = session.query(Users.name, Users.address, UserType.title).join(UserType, isouter=True).all() # select users.name, users.address, usertype.title from users left join usertype on usertype.id = users.utid;
print(ret) # [('Aimer', '南城', '超级会员'), ('Jack', '石排', '超级会员'), ('Timmy', '万江', '白金会员'), ('Kevin', '横沥', '黑金会员'), ('Yeung', '横沥', '黑金会员')]
- 方法三 -> .union() 和 .union_all() -> 上下连表
# .union() -> 没有去重功能
q1 = session.query(Users.name).filter(Users.id <= 2)
q2 = session.query(UserType.title)
ret = q1.union(q2).all() # select name from users where id <= 2 union select title from usertype;
print(ret) # [('Kevin',), ('Yeung',), ('超级会员',), ('白金会员',), ('黑金会员',)]
# .union_all() -> 自带去重功能
q1 = session.query(Users.name).filter(Users.id <= 2)
q2 = session.query(UserType.title)
ret = q1.union_all(q2).all() # select name from users where id <= 2 union all select title from usertype;
print(ret) # [('Kevin',), ('Yeung',), ('超级会员',), ('白金会员',), ('黑金会员',)]
- relationship() -> 简化连表获取数据的操作 -> 在 django 中也有类似操作
# 导入 relationship
from sqlalchemy.orm import relationship
- relationship('从表的类名', backref='从表使用的变量名')
- backref="从表使用的变量名",所定义的变量名是给当从表获取主表数据的时候使用
- 在主表类中(即:有外键的类)中调用 relationship() 方法,且 relationship() 不会影响表的创建
class Users(Base):
__tablename__ = 'users'
…………
user_type = relationship('UserType', backref='xxoo')
- 正向查询 -> 主表获取从表的数据
# 当调用了 relationship() 方法的时候,会将从表的所有数据放进 user_type 变量里面,当要获取与主表数据相关的从表数据的时候,user_type 就会返回与主表数据相关的从表数据的对象
ret = session.query(Users).all()
for row in ret:
print(row.user_type.__dict__) # {'_sa_instance_state': <sqlalchemy.orm.state.InstanceState object at 0x000002C281E56AC8>, 'title': '黑金会员', 'id': 3}
print(row.name, row.address, row.user_type.title) # Kevin 横沥 黑金会员
- 反向查询 -> 从表获取主表的数据
# 当调用了 relationship() 方法的时候,会将主表的所有数据放进 xxoo 变量里面,当要获取与从表数据相关的主表数据的时候,xxoo 就会返回与从表数据相关的主表数据的列表
ret2 = session.query(UserType).all()
for row in ret2:
print(row.title, row.xxoo) # 超级会员 [<__main__.Users object at 0x000001830D6E71D0>, <__main__.Users object at 0x000001830D6E7240>]
print(row.xxoo[0].name) # Aimer
- 子查询
ret = session.query(Users.name, Users.address).filter(Users.id.in_(session.query(Users.id).filter(Users.id < 3))).all() # select name,address from users where id in (select id from users where id < 3);
print(ret) # [('Kevin', '横沥'), ('Yeung', '横沥')]
- 临时表
# .subquery()
sql = session.query(Users).filter(Users.id < 5).subquery() # 使用 .subquery() 创建临时表
# 注意子句中需要使用 c 来调用字段内容
ret = session.query(sql).filter(sql.c.id > 2).all() # 使用临时表 -> select * from (select * from users where id < 5) as A where A.id > 2
print(ret) # [(4, 'Timmy', 25, '万江', 2)]
- 在 select 语句中的字段名那一块可以使用 select 语句 -> select 字段名,(select查询语句) from 表名 where 条件
# 导入 aliased
from sqlalchemy.orm import aliased
# .as_scalar() -> 在SQL语句外面加了()
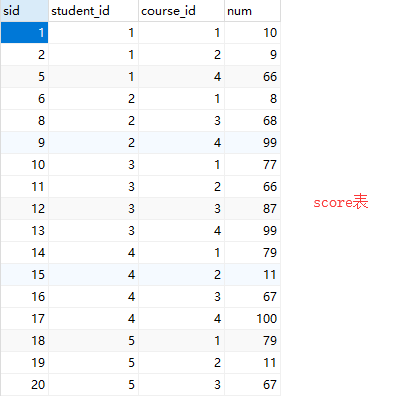
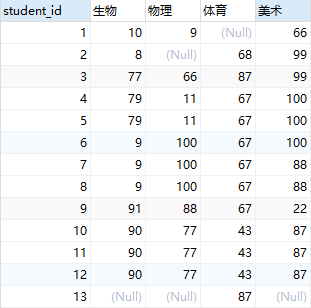
# 该例子在 Mysql 练习中的 显示所有学生的生物、物理、体育、美术四门的课程成绩
score_alias1 = aliased(Score, name='score_alias1') # 给表起别名
score_alias2 = aliased(Score, name='score_alias2') # 给表起别名
result = session.query(
score_alias1.student_id,
session.query(score_alias2.num).filter(score_alias1.student_id == score_alias2.student_id, score_alias2.course_id == 1).as_scalar(),
session.query(score_alias2.num).filter(score_alias1.student_id == score_alias2.student_id, score_alias2.course_id == 2).as_scalar(),
session.query(score_alias2.num).filter(score_alias1.student_id == score_alias2.student_id, score_alias2.course_id == 3).as_scalar(),
session.query(score_alias2.num).filter(score_alias1.student_id == score_alias2.student_id, score_alias2.course_id == 4).as_scalar(),
).group_by(score_alias1.student_id).all()
print(result) # [(1, 10, 9, None, 66), (2, 8, None, 68, 99), (3, 77, 66, 87, 99), (4, 79, 11, 67, 100), (5, 79, 11, 67, 100), (6, 9, 100, 67, 100), (7, 9, 100, 67, 88), (8, 9, 100, 67, 88), (9, 91, 88, 67, 22), (10, 90, 77, 43, 87), (11, 90, 77, 43, 87), (12, 90, 77, 43, 87), (13, None, None, 87, None)]
# SQL语句
select
student_id,
(select num from score as s2 where s2.student_id = s1.student_id and course_id = 1) as '生物',
(select num from score as s2 where s2.student_id = s1.student_id and course_id = 2) as '物理',
(select num from score as s2 where s2.student_id = s1.student_id and course_id = 3) as '体育',
(select num from score as s2 where s2.student_id = s1.student_id and course_id = 4) as '美术'
from
score as s1
group by
student_id;
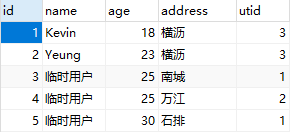
8. 修改数据
- 返回值: 受影响行数的数量
# .update()
ret = session.query(Users).filter(Users.id > 2).update({"name": "临时用户"}) # update users set name = '临时用户' where id > 2;
print(reg) # 3
- 在字符串类型的数据后面拼接上其他字符串
session.query(Users).filter(Users.id > 2).update({Users.name: Users.name + '_test'}, synchronize_session=False)
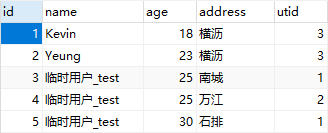
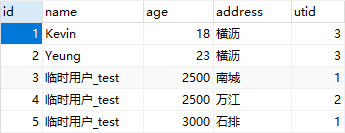
- 在数字类型的数据基础上进行运算
session.query(Users).filter(Users.id > 2).update({Users.age: Users.age * 100}, synchronize_session='evaluate')
9. 删除数据
- 返回值: 受影响行数的数量
# .delete()
session.query(Users).filter(Users.id > 2).delete() # delete from users where id>2;

← MySQLdb 模块 PIL 图像处理模块 →